Hibernate 性能优化法则
Hibernate 是 Java EE 应用中流行的 JPA 框架,简单易用,但很多使用过 Hibernate 的开发者都普遍反映 Hibernate 性能低下。究其原因,还是使用者没有对 Hibernate 进行过深入理解,对 Hibernate 的应用也只是浮于表面。本文介绍了几种简单实现 Hibernate 性能优化的方法。
启用 Hibernate 数据统计策略
没有测量就没有优化。启用 Hibernate 数据统计策略,用来做优化前后的数据对比。
将 hibernate.generate_statistics置为true,日志级别org.hibernate.stat置为DEBUG,Hibernate 会收集内部统计数据,比如查询的性能、缓存命中情况等。
做到这一步,你可以避免常见的问题,比如,查询缓慢,查询次数太多,缓存没有使用等情况。还有一点要注意,数据库的测试数据量大小对于查询结果影响也很大。
改进慢查询
慢查询并不是一个真正的 JPA 或 Hibernate 的问题。这种性能问题在每一个框架中都有可能发生,甚至是普通的 SQL 或者 JDBC,这时就需要在固定的 SQL 和数据库级别进行分析。如果你选择这样做了,那你就不能用 JPQL 或 Criteria API 来处理复杂或优化 SQL 查询。在这种情况下,需要使用本机查询来执行本地的SQL语句,在其中您可以使用所有 SQL 和专有的数据库功能。但是,这也有一个缺点。你得到是一个 Object[],而不是你从 JPQL 获得强类型的结果。您可以通过编程方式或通过@SqlResultSetMapping 注解映射到 Object[] 。
选择正确的 FetchType
使用错误的 FetchType 可能会导致在执行加载所需的实体时,查询数量巨大。
- FetchType.LAZY:懒加载,加载一个实体时,定义懒加载的属性不会马上从数据库中加载。
- FetchType.EAGER:急加载,加载一个实体时,定义急加载的属性会立即从数据库中加载。
比方 User 类有两个属性,name 跟 address,就像一般的系统,登录后用户名是需要在右上角显示出来的,此属性用到的几率极大,要马上到数据库查,用急加载;而用户地址大多数情况下不需要显示出来,只有在查看用户资料是才需要显示,需要用了才查数据库,用懒加载就好了。
所以,要正确的使用 FetchType。
使用特定的查询语句
当真正需要急加载时,可以使用特定的查询语句,比如用 FETCH JOIN 代替 JOIN。FETCH 会告诉 Hibernate 不单单是查询两个实体,还要把实体相关的实体从数据库查出来。
重量级操作交给数据库处理
Java 的处理逻辑能力并不一定比数据库本身的处理能力强,所以有些大数据集操作可以交给数据库处理。
使用缓存
在相同数据经常被读取的情况下,使用缓存来提高查询效率。
Hibernate 提供了三种缓存方式来组合使用。
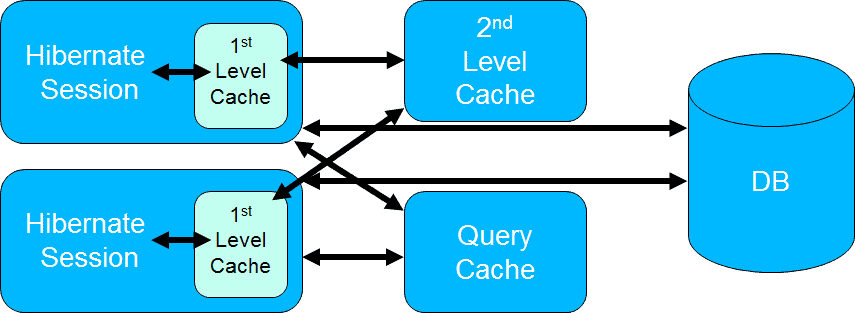
- 1st level cache(一级缓存):默认情况下是激活的,用来缓存在当前会话中使用的所有实体。
- 2nd level cache(二级缓存):也可以存储实体,需要通过在 persistence.xml 设置
shared-cache-mode属性。特定实体的高速缓存可以通过在实体上添加javax.persistence.Cacheable或org.hibernate.annotations.Cache注解来实现。 - query cache(查询缓存):不存储实体。它缓存查询结果,并且只包含实体引用和标量值。你需要通过在 persistence.xml 文件中设置
hibernate.cache.use_query_cache属性和 Query 的cacheable属性来激活该缓存。
在更新和删除时使用批量处理
JPA 2.1 新增了 CriteriaUpdate 和 CriteriaDelete 接口。
- CriteriaUpdate 接口定义用于使用 Criteria API 批量更新的操作功能。该批量更新操作直接映射到数据库的更新操作,会绕过任何乐观锁检查。
- CriteriaDelete 接口定义用于使用 Criteria API 批量删除的操作功能。该批量删除操作直接映射到数据库的删除操作。持久化上下文不会同步批量删除的结果。

